Troubleshooting Poor Performance of a Client's Ext-based Application
The other week I delivered an Ext-based application to a customer. Shortly after they were in touch to say that it was slow. Although an application that relies on >500KB of JavaScript is never going to be super-fast it shouldn't be taking 10 seconds to open each new tab within the application, which is what they were experiencing.
Delays in the region of 10s to open a page make an application almost useless as most users just won't wait that long for stuff to happen. Needless to say I set about trying to work out why it was happening.
From the off the problem appeared to be "their side". Performance on the server I'd been developing was as good as you'd expect from an Ext-based application. Resisting the temptation to simply say "Works fine here!" (hey, I'm a pro, I'd never say that to a paying customer) I got the customer to log the browser-server transactions, so I could take a closer look. Not having access to their servers meant I couldn't debug it directly.
To record the HTTP transaction log I had them install the free Basic Edition of HttpWatch. All they had to do then was start recording, open the application, open a new form, open a new document, edit the document, save the document etc and then stop recording. The result is a .HWL file which I can then open in my version of HttpWatch's "Studio". I can then see all headers, response code and the amount of time taken for all transactions involved.
On opening the the HWL file it was almost immediately obvious there was a problem. Here's a view of the transactions involved:
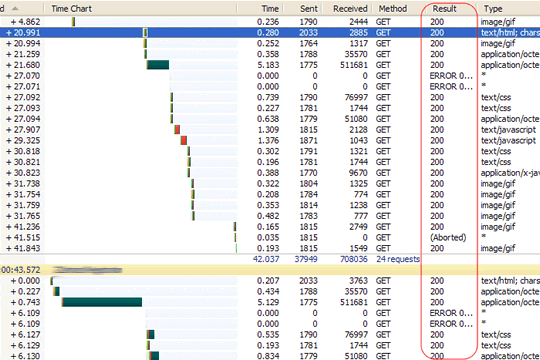
Notice the Result column. This shows the HTTP status code returned. A code of 200 means everything was "ok". This is "ok" but not what we'd expect to see for all transactions. Especially on subsequent requests for the same resource. What we'd expect is a code of 304 which tells the browser it hasn't changed and it can use the local cached copy instead. Because this isn't happening the cache is never used and so it runs unacceptably slowly.
Why is it doing this though?
Drilling down in to each individual transaction I noticed something common to them all. For each GET request the server was returning a Cache-Control header of no-cache.

While we expect this for certain URLs, such as those ending in ?OpenAgent or ?OpenForm, we certainly wouldn't expect it of requests for files ending in CSS, JS or GIF. The image above shows a request for a JS file which is 500KB in size. You definitely want something like that cached browser-side!
What could be causing this?
As far as I know the only way for this to happen would be if a developer or administrator had previously added a Web Site Rule to the server's directory which looked something like this:
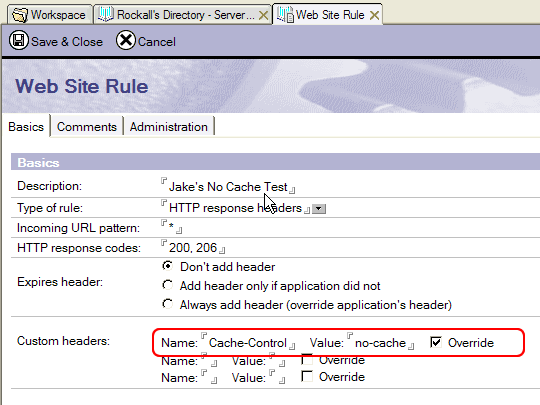
The effect of applying this rule, which I verified by testing on my own server (following a restart), is that the server tells the browser not to cache anything from it.
While I imagine this might have solved whatever problems the developer was having with caching at the time it has - in turn - created other problems, as they're finding now.
It should go without saying, but I'll say it anyway -- never ever use a system-wide configuration change like this as a quick fix to a problem you're having. If you do then you at least need to be mindful of any adverse effects on other applications.
My advise to the customer was that the only real solution was to remove the rule. Although, as I warned them, this could then "break" any systems that have been developed with it in place.
An alternative would be to add subsequent Rules which tell the browser to using caching if the URL ends in *.js etc and hope that it trumps the Rule already in place.
I am always amazed at how many Domino apps I come accross that just "live with" these sort of front end performance issues. I always try to use site rule documents for the exact opposite purpose - to aggresively cache anything that is non-volatile by using the expires header. This avoids the whole browser-server HTTP 304 round trip entirely. I use a DXL based build process to force resource name and reference changes to ensure that when design changes are made, all browser clients will go back to the server to get the new versions.
The following book on this topic has become an absolute bible for me: {Link}
Thanks Jeff. Interesting idea. I just added a rule to set an Expires header (31 days away) and a Cache-control header of "public" to all the Ext .js files. I cleared the browser's cache and reloaded. The new headers were in place. However, when I reload the page, the browser still asks the server if it's been modified and the server replies no. Should that still happen? I'd have thought not.
Jake
No, ideally your browser should not revalidate those files with the server for another 31 days. This stuff is never an exact science of course, as any user can configure their browser (or intermediate proxy cache for that matter) to behave however they want with respect to local caching of content.
Check your browser settings (FF: about:config). In my experience the expires header usually works well with most browser defaults.
Jake, another way to save bandwidth with Ext is to gzip the ext-all.js file. That ~500K file will then reduce to less than ~150K. Tim has some info on this here: {Link}
The only change I would make is to not use .gz as an extension but instead just put your gzip content in a folder called gzip and then have your web site rule look for that pattern instead.
Additionally, you can use Ext's "build your own" feature to build a version of Ext that only includes what you are using and then gzip that instead. Just look on their download page here: {Link} for this info.
Jack
Now, what's really annoying is, if you've done all that and added expires headers, just to find out, that your company decides to deploy a browser setting by policy, that makes it reload each page completely every time (because some stupid Intranet applications based on oh so cool Oracle and Struts can't cope with the standard setting). As if it wasn't bad enough to develop for IE 6 ...
One more hint: If you are using an Expires header anyway, why not make it a "far future Expires header" (as Yahoo puts it), like 1 year ahead or even more? If any of your cached resources change, you will have to make sure that they are reloaded, anyway. Adding a version number to the file name still looks like the best approach to me and using an automated build process (as mentioned by Jeff) can even make it pretty easy to do.
Talking about gzipping JS files almost automatically brings up the topic of minifying JS (or not). There's been a lot of argument pro and con on this, and definitely, when compared, gzipping alone is far more effective than minifying alone. But if you are willing to take the hassle and generate gzipped versions anyway (unless you're running a version of Domino that can do it on-the-fly, which will not be before 8.5, if I remember right), in my mind you can just as well minify them. Even more so, if you choose to provide an uncompressed version as well for browsers that might have trouble with gzipped contents (see {Link}
Also, I'd like to take the opportunity to take up the cudgels for Yahoo's YSlow. I've seen a number of bloggers questioning the usefulness of this tool. Usually the argumentation is like: Hey, my site loads blistering fast anyway, why do I get a page rank of "D" then? In my eyes, this is a misunderstanding. YSlow is not intended to rate the absolute performance of a site (under given conditions like bandwidth, CPU power, browser's rendering speed and so on). It's really just about adopting patterns. To what extend it pays off will depend a lot of factors, but there's no reason to not do it right in the fist place.
And by the way: Your site's resourced could use a far future Expires headers as well, Jake. ;-)
Well, at least the problem wasn't with ExtJS. And I take offense -- an application with >500KB of JavaScript can definitely be fast, just not the first time you access it, of course. ;)
We have a combination of about 1.23 MB of custom code on top of the ExtJS code. I created a custom script file to pull all the source from our development database using WebDAV, combine it using JSBuilder then compress it using yuicompressor, gzip it and then upload it to the domino/html directory. The resulting gziped file is 105 KB.
Along side this we also have CSS, TinyMCE and ExtJS 2 which we have gone through similar conversions. TinyMCE was interesting because it has been written to be gzipped on the fly. I have taken their routine and done it statically so we have about a 60 KB footprint.
As you can see we have a fairly hefy footprint. So we have also invoked browser caching and set large expire periods. We have placed all our web resources into the domino html directory as mentioned above (some performance tests we did determine this was faster then in the DB). We have also setup versions in our JS paths we if we need to rollout changes we update the version numbers (/cwo2.01 is changed to /cwo2.02).
Our load time drastically improved using these methods. We also moved around the JS includes into the bottom of out HTML as mentioned in the YUI Slow performance tool and that seemed to do the trick.